Bất biến
SUY LUẬN NHÂN QUẢ CHO HỌC MÁY - KỲ 10
Bài viết này thuộc chuỗi bài viết về “Suy luận Nhân quả cho Học máy”. Hãy cùng đọc thêm các bài viết có cùng chủ đề tại đây
Để hiểu thêm kiến thức về Suy luận Nhân quả, hãy cùng tìm đọc chuỗi bài viết về “Suy luận Nhân quả với Python” tại đây và “60 Giây Nhân quả với Python” tại đây
Để tự tin dự báo ngoài tập dữ liệu huấn luyện, chúng ta cần một mô hình mạnh trước sự thay đổi của phân phối xác suất. Cụ thể, đó là một mô hình có khả năng học các quy luật loại trừ các mối quan hệ tương quan chỉ xuất hiện trong một vài tập dữ liệu (môi trường) cá biệt. Thay vào đó, nó chỉ dựa vào các thuộc tính có tác động đến mục tiêu trong mọi môi trường.
Vậy làm thế nào để tạo ra một mô hình như vậy? Chúng ta có thể đơn thuần huấn luyện mô hình của mình trên dữ liệu từ nhiều môi trường khác nhau, như chúng ta thường làm trong học máy (tạm phớt lờ giả định i.i.d.). Tuy nhiên, làm như vậy chỉ có thể cung cấp cho ta một mô hình tổng quát hoá các môi trường mà nó đã trải qua (và các môi trường nội suy từ chúng, nếu ta sử dụng một mục tiêu đủ mạnh). Hơn thế, chúng ta mong muốn mô hình tổng quát hoá vượt ra ngoài giới hạn của các môi trường mà nó đã được huấn luyện và có thể ngoại suy cho các môi trường mới mà nó chưa từng trải qua (hay không lường trước được). Thuộc tính mà chúng ta đang tìm kiếm – khả năng hoạt động tối ưu trong mọi môi trường - được gọi là bất biến.
Tồn tại mối liên hệ chặt chẽ giữa nhân quả và bất biến. Trên thực tế, các mối quan hệ nhân quả về bản chất đều bất biến. Nhiều mối quan hệ nhân quả hiển nhiên được thiết lập bằng việc quan sát sự tồn tại của mối quan hệ đó trong mọi hoàn cảnh.
Hãy cùng tìm hiểu các định luật vật lý được phát hiện như thế nào. Chúng được khám phá bằng cách thực hiện một loạt các thí nghiệm trong các điều kiện khác nhau, giám sát các mối quan hệ và dạng phương trình mô tả chúng. Trong quá trình khám phá các định luật tự nhiên, một số thử nghiệm có thể không cho ra kết quả như kỳ vọng. Khi định luật bị vi phạm, nó cho ta biết cần phải có sự điều chỉnh để đảm bảo tính bất biến trong mọi môi trường.
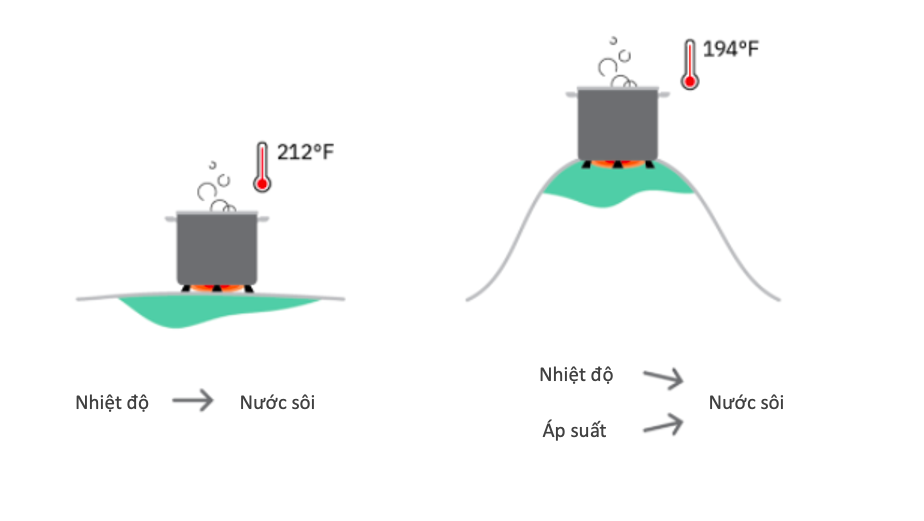
Ví dụ, nước sôi ở 100 °C (212 °F). Chúng ta có thể quan sát điều này ở khắp mọi nơi, và ta có một biểu đồ nhân quả đơn giản: nhiệt độ -> nước sôi. Chúng ta đã học được mối quan hệ bất biến này trong tất cả các môi trường mà chúng ta đã quan sát.
Sau đó, một thí nghiệm mới được tiến hành trên đỉnh một ngọn núi cao cho thấy trên đỉnh núi, nước sôi ở nhiệt độ thấp hơn một chút. Sau một vài thử nghiệm khác, chúng ta cải tiến mô hình nhân quả của mình khi nhận ra rằng cả nhiệt độ và áp suất đều ảnh hưởng đến điểm sôi của nước, và mối quan hệ bất biến thực sự phức tạp hơn.
Biểu diễn toán học của quan hệ nhân quả giúp cho khái niệm bất biến và môi trường trở nên chính xác hơn. Môi trường được xác định bằng các biện pháp can thiệp trong biểu đồ nhân quả. Mỗi một can thiệp làm thay đổi mô hình tạo lập dữ liệu, và khiến quan hệ tương quan giữa các biến trong biểu đồ có thể trở nên khác nhau. Tuy nhiên, mối quan hệ nhân quả trực tiếp bất biến: nếu một nút trong biểu đồ nhân quả chỉ phụ thuộc và ba biến, và nếu mô hình nhân quả đúng, thì nút này phụ thuộc vào ba biến đó, theo một cách giống nhau, bất kể dưới hình thức can thiệp nào. Một can thiệp có thể giới hạn các giá trị đầu vào của các tác nhân, nhưng bản thân mối quan hệ nhân quả không bị thay đổi. Nói cách khác, việc thay đổi đối số không làm thay đổi hàm số.
Bất biến và học máy
Trong học máy, chúng ta chủ yếu quan tâm đến việc sử dụng các thuộc tính để dự báo mục tiêu. Do đó, chúng ta có xu hướng chọn các thuộc tính có ích cho khả năng dự báo của mô hình. Ngược lại, biểu đồ nhân quả được thiết lập dựa trên kiến thức chuyên môn và các quan hệ thống kê độc lập, vì vậy có thể mã hoá được một cấu trúc phụ thuộc phức tạp hơn nhiều. Tuy nhiên, không phải lúc nào chúng ta cũng quan tâm đến toàn bộ biểu đồ nhân quả. Chúng ta có thể chỉ quan tâm đến nguyên nhân của một biến mục tiêu cụ thể. Điều này đưa ta đến gần hơn với các phương pháp học máy quen thuộc.
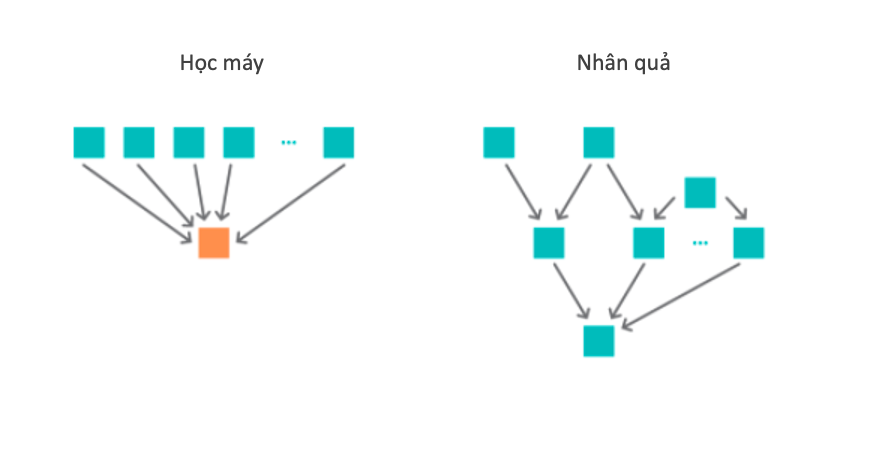
Tiếp theo chúng ta sẽ xem xét hai cách tiếp cận để kết hợp bất biến do nhân quả và học máy. Cách thứ nhất là dự đoán theo nhân quả bất biến: sử dụng khái niệm bất biến để suy ra nguyên nhân trực tiếp của biến mục tiêu. Hình thức khám phá nhân quả giới hạn này (tìm ra cấu trúc của một phần nhỏ trong biểu đồ mà chúng ta quan tâm) thích hợp cho các vấn đề có các biến được xác định rõ ràng sao cho một mô hình nhân quả cấu trúc (SCM) (hoặc ít nhất là đồ thị nhân quả) có thể được tạo ra, trên nguyên tắc, nếu không có trong thực tế.
Tuy nhiên, không phải tất cả mọi vấn đề đều có thể giải quyết được với SCM. Trong phần tới, chúng ta sẽ cùng tìm hiểu việc giảm thiểu rủi ro bất biến, trong đó ta gác lại biểu đồ nhân quả và tìm kiếm yếu tố dự báo bất biến trong nhiều môi trường. Chúng ta sẽ không thu được bất kỳ điều gì về cấu trúc biểu đồ từ quy trình này, nhưng chúng ta có thể thu được một mô hình dự báo với năng lực ngoại suy được cải thiện đáng kể.
Comments