Quan hệ Nhân quả mang lại lợi ích gì?
SUY LUẬN NHÂN QUẢ CHO HỌC MÁY - KỲ 3
Bài viết này thuộc chuỗi bài viết về “Suy luận Nhân quả cho Học máy”. Hãy cùng đọc thêm các bài viết có cùng chủ đề tại đây
Để hiểu thêm kiến thức về Suy luận Nhân quả, hãy cùng tìm đọc chuỗi bài viết về “Suy luận Nhân quả với Python” tại đây và “60 Giây Nhân quả với Python” tại đây
Suy luận nhân quả cung cấp một bộ công cụ cho phép chúng ta tìm hiểu nguyên nhân của một sự việc. Điều này là một bước tiến so với các phương pháp tiếp cận thống kê hoặc học máy truyền thống tập trung vào việc dự báo kết quả và quan tâm đến việc xác định các mối liên hệ.
Nhân quả từ lâu đã luôn là mối quan tâm của con người trên phương diện triết học, nhưng chỉ đến nửa sau của thế kỷ 20 (nhờ công trình của các nhà nghiên cứu tiên phong như Donald Rubin hay Judea Pearl), một bộ khung toán học cho quan hệ nhân quả mới ra đời. Trong những năm gần đây, sự bùng nổ của học máy đã thúc đẩy sự phát triển của suy luận nhân quả và thu hút thêm nhiều nhà nghiên cứu đến với lĩnh vực này.
Xác định tác động nhân quả giúp chúng ta có hiểu biết về nhiều sự việc: ví dụ, hành vi của người dùng trong các hệ thống trực tuyến, ảnh hưởng của các chính sách xã hội, hay các yếu tố nguy cơ của bệnh tật. Các câu hỏi về nhân quả cũng rất quan trọng đối với việc thiết kế các ứng dụng dựa theo hướng dữ liệu. Ví dụ, các đề xuất của thuật toán ảnh hưởng đến quyết định tiêu dùng như thế nào? Chúng ảnh hưởng như thế nào đến kết quả học tập của học sinh hay tính hiệu quả công việc của bác sĩ? Tất cả những câu hỏi này đều không dễ trả lời và đòi hỏi chúng ta phải suy nghĩ phản thực: điều gì sẽ xảy ra trong một thế giới với một hệ thống, chính sách hay can thiệp khác? Nếu không có suy luận nhân quả, các phương pháp dựa trên quan hệ tương quan có thể khiến ta lạc lối.
Điều này chứng tỏ rằng việc học quan hệ nhân quả là một thử thách không đơn giản. Nhìn chung, chúng ta có thể tự nhận thấy hai trường hợp: thứ nhất, chúng ta có thể chủ động can thiệp vào hệ thống mà chúng ta đang xây dựng mô hình và lấy dữ liệu thử nghiệm; thứ hai, chúng ta chỉ có dữ liệu quan sát.
Tiêu chuẩn vàng trong việc thiết lập các tác động nhân quả là Thử nghiệm đối chứng ngẫu nhiên (RCT) thuộc vào loại dữ liệu thử nghiệm. Trong RCT, chúng ta cố gắng thiết kế các tổng thể tương tự bằng cách chỉ định ngẫu nhiên (vì việc chọn các tổng thể theo cách thủ công có thể gây ra các thiên lệch chọn ngăn cản việc tìm hiểu các mối quan hệ nhân quả), và chỉ áp dụng can thiệp cho một tổng thể. Từ đó, chúng ta đo lường tác động nhân quả của việc thay đổi một biến số bằng với sự chêch lệch của một đại lượng mà ta quan tâm giữa hai tổng thể.
RCT được dùng để đánh giá một mối quan hệ nhân quả cụ thể có đúng hay không. Tuy nhiên, trong thực tế các thử nghiệm không phải lúc nào cũng có thể thực hiện được, và ngay cả khi thực hiện được, không phải lúc nào chúng cũng đáp ứng được các quy chuẩn về đạo đức (ví dụ, từ chối điều trị cho bệnh nhân với một phương pháp điều trị được cho là có hiệu quả, hay thử một thuật toán tổng hợp tin tức được thiết kế với mục đích tác động đến tâm trạng của người dùng khi không được cho phép). Trong một số trường hợp, chúng ta có thể tìm thấy các thử nghiệm diễn ra một cách tự nhiên. Trong trường hợp ít mong đợi nhất, chúng ta chỉ có thể cố gắng suy ra quan hệ nhân quả từ dữ liệu quan sát.
Nhìn chung, điều này gần như là không thể, và ít nhất chúng ta phải áp đặt một số giả định trong quá trình mô hình hoá. May mắn thay, có một số phương pháp tiêu chuẩn để thực hiện điều này. Với mục đích tìm hiểu một cách trực quan, chúng tôi sẽ giới thiệu Mô hình Nhân quả cấu trúc (SCM) của Judea Pearl trong chương này.
Bậc thang nhân quả
Trong cuốn sách “The Book of Why”, Judea Pearl, nhà khoa học của nhiều công trình nền tảng về quan hệ nhân quả, đã mô tả ba loại suy luận mà chúng ta có thể thực hiện giống như việc bước lên những nấc thang. Những nấc thang này cho ta biết khi nào quan hệ nhân quả là cần thiết và chúng có ích như thế nào.
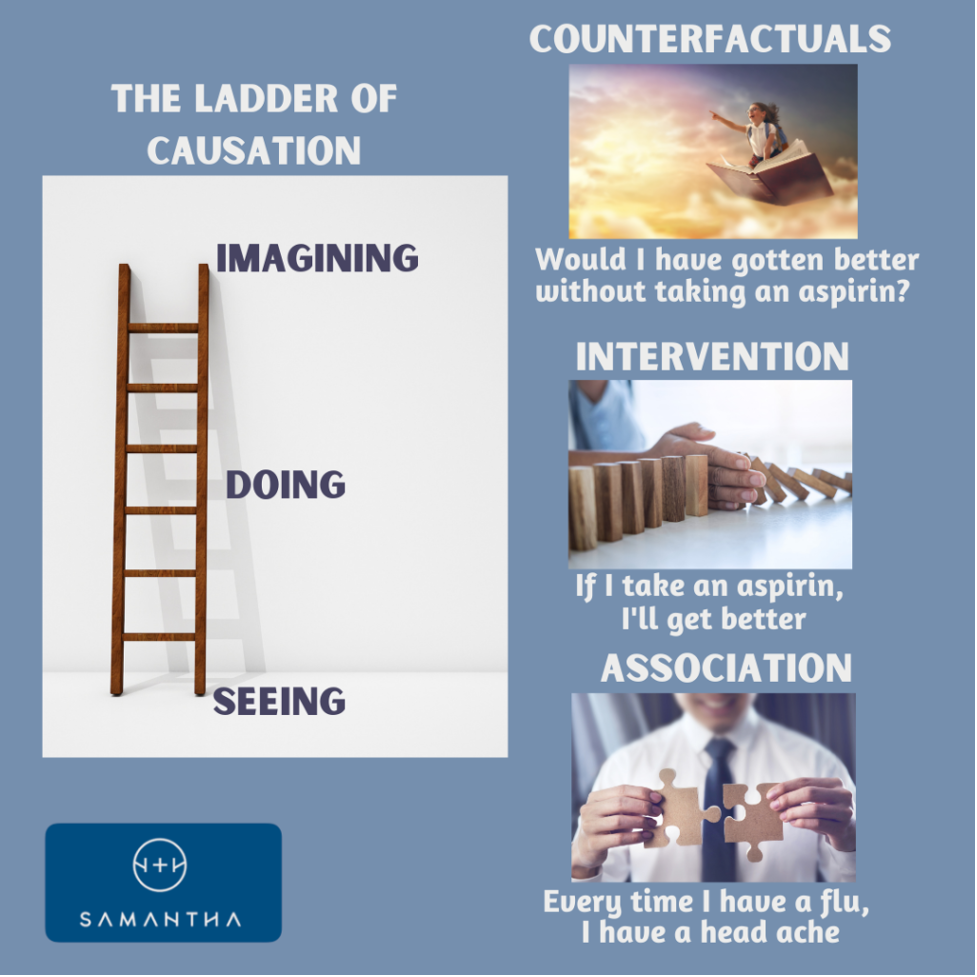
Ở nấc thang đầu tiên, chúng ta có thể sử dụng suy luận thống kê và dự báo. Điều này bao gồm hầu hết những gì một mô hình học máy có thể thực hiện. Chúng ta có thể đưa ra các dự báo rất phức tạp, suy đoán các biến ẩn trong các mô hình tạo mẫu (generative model) sâu và phức tạp hoặc phân cụm dữ liệu theo các mối quan hệ tinh vi. Tất cả những điều này nằm ở nấc thang đầu tiên. Ví dụ, một ngân hàng muốn dự đoán các khoản vay kinh doanh hiện tại có khả năng vỡ nợ hay không, do đó, ngân hàng có thể đưa ra các dự báo tài chính về khả năng thua lỗ.
Nấc thang thứ hai là suy luận can thiệp. Loại suy luận này cho phép chúng ta dự đoán điều gì sẽ xảy ra khi một hệ thống bị thay đổi. Nó cho phép chúng ta mô tả những đặc điểm nào là riêng biệt chính xác đối với những quan sát đã được thực hiện, và những đặc điểm nào không thay đổi trong các hoàn cảnh mới. Loại suy luận này đòi hỏi mô hình nhân quả. Can thiệp là một hành động cơ bản trong quan hệ nhân quả và sẽ được thảo luận trong chương này. Ví dụ, một ngân hàng muốn giảm số lượng các khoản vay vỡ nợ và xem xét thay đổi các chính sách cho vay. Việc dự đoán điều gì sẽ xảy ra do kết quả của can thiệp này đòi hỏi ngân hàng phải hiểu được các quan hệ nhân quả ảnh hưởng đến việc vỡ nợ.
Nấc thang thứ ba là suy luận phản thực. Ở đây, chúng ta không chỉ nói về những gì đã xảy ra mà còn về những gì có thể đã xảy ra nếu hoàn cảnh khác đi. Suy luận phản thực đòi hỏi một mô hình nhân quả cụ thể chính xác hơn suy luận can thiệp. Hình thức suy luận này rất mạnh, cung cấp công cụ toán học để đo lường trong các thế giới song song, nơi các sự kiện diễn ra khác nhau. Ví dụ, một ngân hàng muốn biết khả năng sinh lời của một khoản vay là bao nhiêu, ngân hàng phải đưa ra nhiều mức lãi suất khác so với mức mà ngân hàng đang sử dụng.
Đến đây chúng tôi hy vọng bạn đồng ý rằng có rất nhiều điều liên quan và cần khám phá về quan hệ nhân quả. Tuy nhiên, chúng ta vẫn chưa nêu ra một định nghĩa thực sự cho quan hệ nhân quả. Có lẽ chúng ta nên mở đầu bằng một điệp khúc quen thuộc: Tương quan không phải là nhân quả!
Comments