Từ Dự báo tới Can thiệp - Phần 2
SUY LUẬN NHÂN QUẢ CHO HỌC MÁY - KỲ 7
Bài viết này thuộc chuỗi bài viết về “Suy luận Nhân quả cho Học máy”. Hãy cùng đọc thêm các bài viết có cùng chủ đề tại đây
Để hiểu thêm kiến thức về Suy luận Nhân quả, hãy cùng tìm đọc chuỗi bài viết về “Suy luận Nhân quả với Python” tại đây và “60 Giây Nhân quả với Python” tại đây
Báo cáo nghiên cứu ứng dụng của Cloudera Fast Forward vào năm 2017 giới thiệu một mô hình về tỷ lệ khách hàng ngưng sử dụng dịch vụ của công ty. Mô hình này được xây dựng dựa trên 20 đặc tính khách hàng của một công ty viễn thông (ví dụ: thời gian đã sử dụng dịch vụ, đặc trưng nhân khẩu học, có đăng ký gói hộ trợ kỹ thuật bổ sung hay không). Để làm điều này, cần sử dụng dữ liệu về khách hàng và tìm hiểu liệu họ có rời đi trong khoảng thời gian đang được nghiên cứu hay không. Vấn đề này có thể trực tiếp quy về bài toán phân loại nhị phân và chúng ta có thể dùng kết quả đầu ra của mô hình để đánh giá khả năng khách hàng rời đi.
Mô hình được sử dụng để đo lường khả năng khách hàng rời đi là một tập hợp của một mô hình tuyến tính, rừng ngẫu nhiên (random forest), và một mạng truyền thẳng (feed-forward neural network). Các tham số gốc (hyperparameter) và quy trình huấn luyện thích hợp có thể tạo ra các mô hình có khả năng đưa ra dự báo tốt bằng cách khai thác những mối quan hệ tương quan tiềm ẩn trong dữ liệu.
Một vấn đề quan trọng khác là làm thế nào để cắt nghĩa các dự báo được đưa ra bởi mô hình. Để giải quyết vấn đề này, LIME (Phép diễn giải cục bộ cho mô hình bất khả tri) đã được áp dụng. Kết quả thu được là tầm quan trọng cục bộ của các đặc tính , hay nói cách khác tầm quan trọng của đặc tính cho từng trường hợp dự báo riêng lẻ. Refractor là một giao diện được thiết lập để tiện cho việc khám phá tầm quan trọng của các đặc tính. Nó làm nổi bật các đặc tính có liên quan chặt chẽ đến khả năng khách hàng rời đi trong từng trường hợp. Cụ thể, nó xếp hạng các đặc tính theo mức ảnh hưởng đến khả năng khách hàng rời đi, và cho phép nhà phân tích thay đổi các đặc tính và xem xét tác động của điều này lên dự báo khả năng khách hàng rời đi.
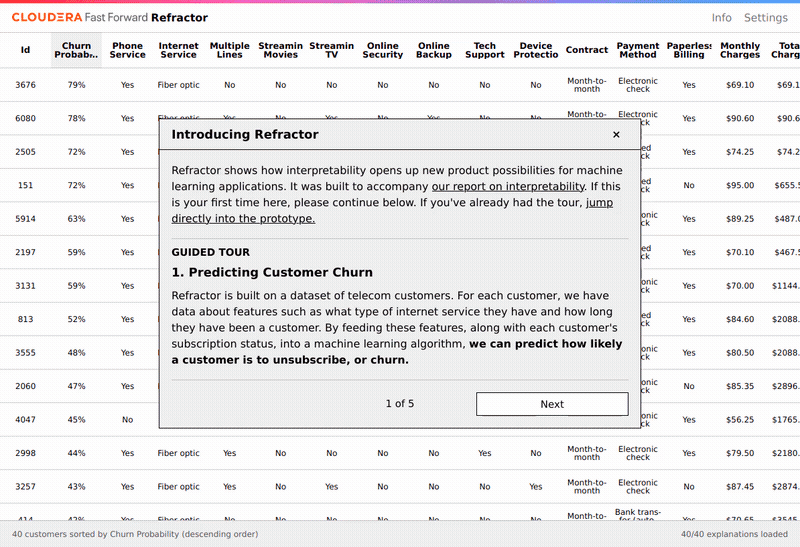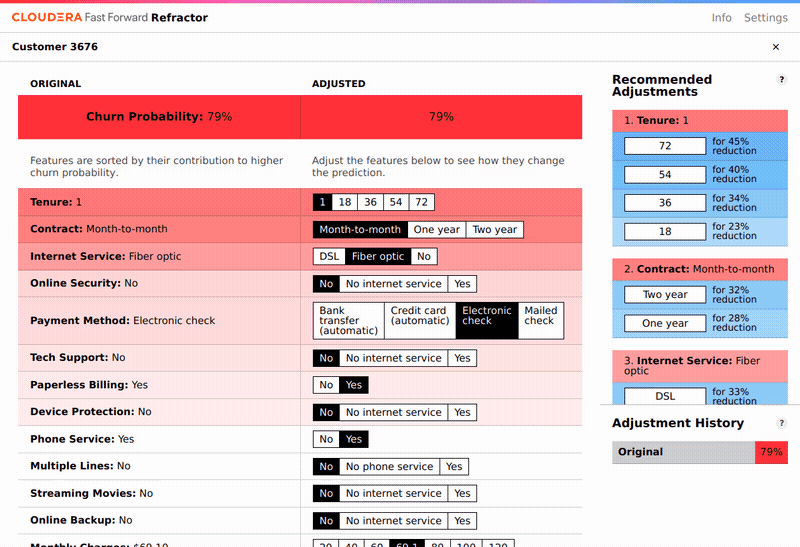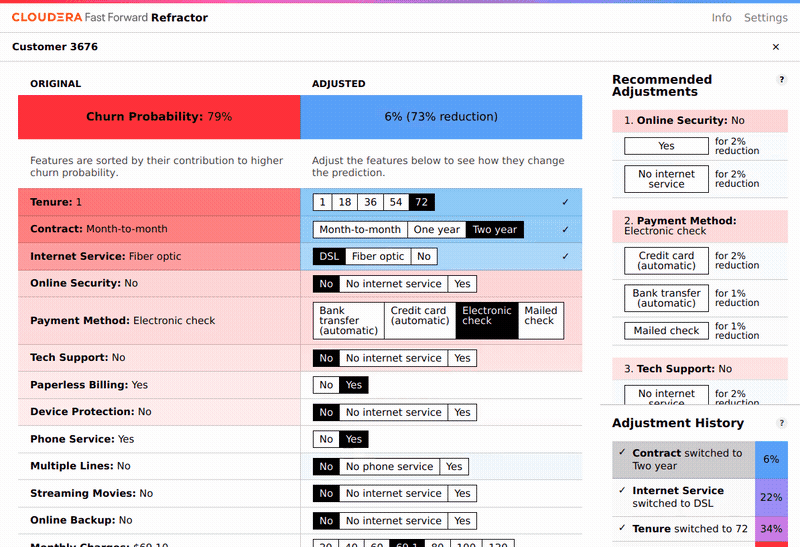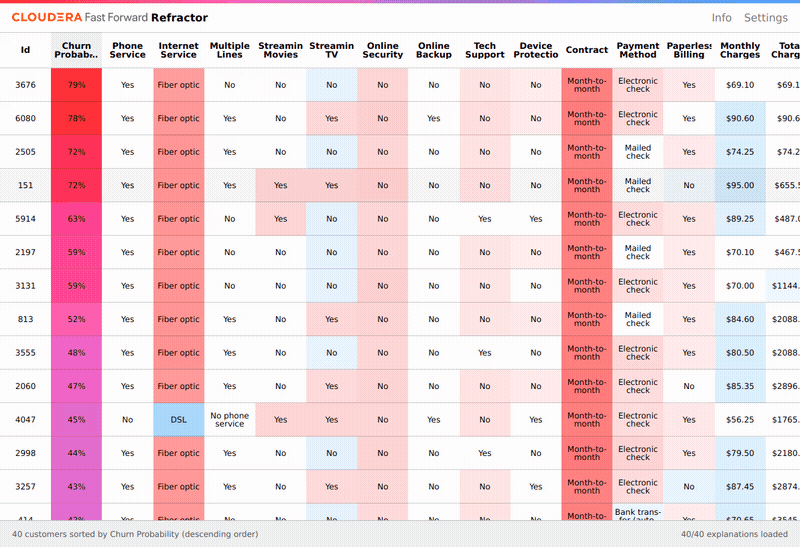
Trên thực tế các đặc tính quan trọng nhất thường không thể thay đổi bằng cách can thiệp (ví dụ: thời gian đã sử dụng dịch vụ). Ngoài ra đây không phải là cách giải thích chính xác những kết quả thu được từ LIME và mô hình dự báo. Đây là xác suất rời đi của một khách hàng trong tập dữ liệu với các đặc tính cụ thể, ví dụ, xác suất rời đi của cùng một khách hàng sẽ thay đổi như thế nào vào năm tới (khi thời gian sử dụng dịch vụ tăng lên một năm), giả sử các đặc tính của khách hàng đó vẫn giữ nguyên.
Có một số đặc tính có thể được thay đổi trong thực tế, ví dụ, công ty viễn thông có thể giảm phí hàng tháng cho khách hàng, hoặc thuyết phục khách hàng thay đổi loại hợp đồng từ hàng tháng sang hàng năm (vì điều này sẽ ảnh hưởng tới khả năng khách hàng rời đi trong ngắn hạn), hoặc nâng cấp dịch vụ từ cáp DSL lên cáp quang.
Biện pháp can thiệp nào trong số những biện pháp trên sẽ có hiệu quả nhất? Nếu chỉ dựa vào mô hình dự báo đã được xây dựng, chúng ta không thể trả lời được câu hỏi này bởi mô hình dựa trên những mối quan hệ tương quan. Thậm chí một mô hình dự báo hoàn hảo với độ chính xác 100% cũng không thể cho chúng ta biết điều đó.
Chúng ta hiểu rằng không thể suy ra quan hệ nhân quả từ các dự báo của mô hình. LIME thường cho chúng ta biết rằng việc kết nối cáp quang băng thông rộng làm tăng xác suất khách hàng rời đi, dù cáp quang nhanh hơn so với cáp DSL. Có vẻ như tốc độ mạng internet không có tác dụng trong trường hợp này. Trên thực tế, LIME cho ta biết có mối tương quan giữa việc sử dụng cáp quang và khả năng khách hàng rời đi, có thể là do một số yếu tố tiềm ẩn (có thể những người thích tốc độ mạng internet nhanh hơn cũng sẵn sàng đổi nhà cung cấp hơn). Sự phân biệt cách giải thích kết quả của mô hình để suy ra quan hệ tương quan hay nhân quả là vô cùng quan trọng.
Để biết điều gì sẽ xảy ra khi can thiệp thay đổi một đặc tính, chúng ta phải tính toán phân phối xác suất của can thiệp (hay ước lượng điểm của nó ). Phân phối này có thể sẽ rất khác với phân phối quan sát. Để đưa ra quyểt định đúng đắn dựa trên bất kỳ phương pháp lý giải mô hình nào, chúng ta cần kết hợp với kiến thức về nhân quả.
Kiến thức nhân quả thông thường khi chưa được biểu diễn dưới dạng biểu đồ, có thể được gọi là kiến thức nghiệp vụ (hoặc chuyên môn) Thực tế, bất kỳ ai làm việc với mô hình đều có xu hướng áp dụng kiến thức nghiệp vụ của họ. Việc chuyển từ mô hình dự báo sang mô hình nhân quả đòi hỏi phải mã hoá các giả định được đưa ra và kiểm định sự tồn tại của các mối quan hệ thống kê được kì vọng dựa vào dữ liệu quan sát (hoặc dữ liệu thử nghiệm, nếu có thể). Việc này giúp ta có thể khám phá các mối quan hệ nhân quả trong hệ thống suy luận định lượng về tác động của các biện pháp can thiệp.
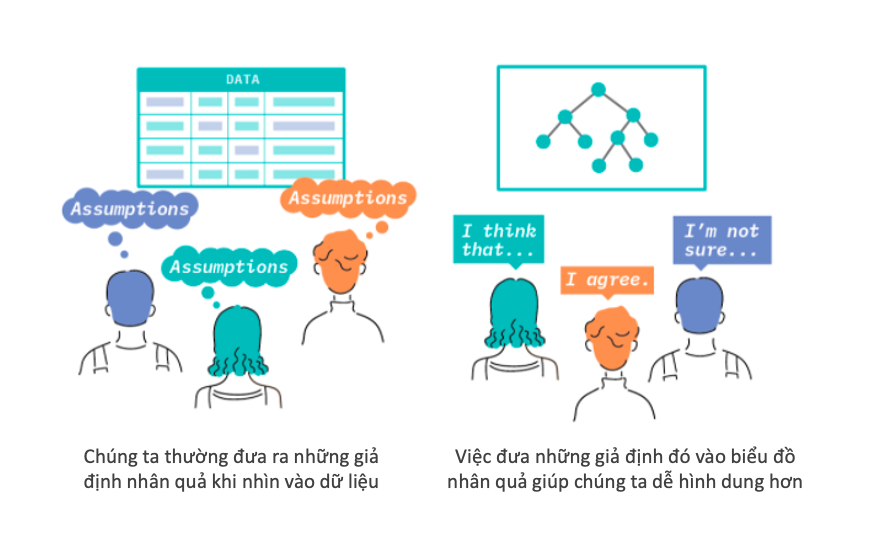
Có thể nói, xây dựng một mô hình nhân quả hữu ích về khả năng khách hàng rời đi là một nhiệm vụ không đơn giản, đòi hỏi cả kiến thức nghiệp vụ và hiểu biết chuyên sâu về kĩ thuật suy luận nhân quả. Trong những chương tiếp theo, chúng ta sẽ quay trở lại vấn đề này và thảo luận về một số kỹ thuật thu hẹp khoảng cách giữa một mô hình nhân quả tiêu chuẩn và học máy có giám sát.
Khi nào chúng ta cần can thiệp?
Vậy khi nào chúng ta cần sử dụng can thiệp và quan hệ nhân quả? Nếu mục tiêu cuối cùng là dự báo với độ chính xác cao (hoặc tối ứu bất kỳ chỉ số đánh giá mô hình nào khác) thì chúng ta nên tận dụng mọi tài nguyên có sẵn. Cụ thể là tận dụng tất cả các biến có thể có mối quan hệ tương quan với đối tượng mà chúng ta đang cố gắng dự báodù chúng có thực sự chi phối kết quả hay không. Tương quan không phải là nhân quả, nhưng tương quan vẫn mang tính dự báo. Mô hình học có giám sát thường vượt trội trong việc phát hiện ra các mối tương quan tiềm ẩn trong dữ liệu.
Sau đây là một số trường hợp mà phương pháp học có giám sát thuần tuý sẽ hữu ích:
- Dự báo khi nào máy móc trong nhà máy bị hỏng
- Dự báo doanh số bán hàng trong quý tới
- Nhận dạng thực thể định danh từ dữ liệu chữ..
Ngược lại, nếu chúng ta muốn dự báo tác động của một can thiệp, chúng ta cần sử dụng quan hệ nhân quả. Ví dụ khi chúng ta muốn xác định:
- Những thay đổi máy móc cần thiết để giảm khả năng hỏng hóc
- Cách tăng doanh số bán hàng trong quý tới
- Tiêu đề bài viết dài hay ngắn thì người xem sẽ truy cập nhiều hơn.
Như vậy, phần này đã nhấn mạnh tầm quan trọng của việc phân biệt dự báo và can thiệp trong cách giải thích mô hình. Điều này tạo nền tảng cho việc xác định khi nào nên sử dụng kiến thức nhân quả vào việc xây dựng mô hình để giải quyết câu hỏi hay mục tiêu được nghiên cứu.
Comments