Phương pháp Giảm thiểu Rủi ro Bất biến Hoạt động như thế nào?
SUY LUẬN NHÂN QUẢ CHO HỌC MÁY - KỲ 13
Bài viết này thuộc chuỗi bài viết về “Suy luận Nhân quả cho Học máy”. Hãy cùng đọc thêm các bài viết có cùng chủ đề tại đây
Để hiểu thêm kiến thức về Suy luận Nhân quả, hãy cùng tìm đọc chuỗi bài viết về “Suy luận Nhân quả với Python” tại đây và “60 Giây Nhân quả với Python” tại đây
Ở kỳ trước, chúng ta đã biết Giảm thiểu rủi ro bất biến (IRM) là phương pháp có thể sử dụng để ước lượng các tương quan bất biến. Tuy nhiên để xác định được các biến giải thích (hay biến dự báo, biến độc lập) bất biến, chúng ta phải cung cấp cho IRM dữ liệu từ nhiều môi trường. Trong Dự đoán nhân quả bất biến (ICP), các môi trường này chính là các tập dữ liệu rời rạc. Chúng ta không cần xác định cấu trúc biểu đồ hay can thiệp liên quan đến môi trường.
Hãy cùng xem xét một ví dụ trong lĩnh vực Thị giác máy tính - nơi thúc đẩy sự định hình phương pháp IRM. Với bài toán xây dựng hệ thống học máy phân biệt bò với lạc đà, hệ thống nhiều khi đưa ra phân loại dựa trên môi trường mà loài động vật đó xuất hiện hơn là dựa trên chính bản thân loài động vật đó. Ví dụ, trong trường hợp này, một con bò xuất hiện trên cát có thể bị phân loại nhầm thành lạc đà do hệ thống Thị giác máy tính đã dựa trên những tương quan giả.
Tuy nhiên, chỉ cung cấp dữ liệu từ nhiều môi trường thì vẫn chưa đủ. Vấn đề của mô hình phân loại tối ưu đa môi trường là tối ưu hoá ràng buộc đồng thời, nghĩa là chúng ta phải tìm cách biểu diễn dữ liệu tối ưu và mô hình phân loại tối ưu đồng thời trên nhiều tập dữ liệu riêng biệt. IRM giảm thiểu vấn đề này thành một vòng lặp tối ưu hoá duy nhất, với thủ thuật sử dụng một mô hình phân loại bất biến và đưa vào điểm phạt thông qua hàm tổn thất
Tổn thất IRM = tổng các môi trường (sai số + điểm phạt)
Sai số ở đây là sai số thông thường chúng ta áp dụng cho bài toán hiện tại, ví dụ, entropy chéo (cross entropy) cho bài toán phân loại, được tính riêng cho từng môi trường. Về chi tiết kỹ thuật, điểm phạt là bình phương độ lớn của độ dốc (gradient) khi cố định mô hình phân loại. Sai số ước lượng độ chính xác của mô hình trong từng môi trường, điểm phạt ước lượng mức độ cải thiện mô hình qua mỗi một “bước nhảy” độ dốc. Điểm phạt trong hàm tổn thất “phạt” độ dốc lớn (tình huống khi mô hình trong một môi trường được cải thiện đáng rất nhiều sau khi kết thúc thêm một lượt huấn luyện (epoch) ).
Bằng cách này chúng ta thu được một mô hình có độ chính xác tối ưu trong mọi môi trường. Nếu không có điểm phạt trong IRM, một mô hình có giá trị hàm tổn thất thấp ngay cả khi hoạt động rất tốt trong môi trường này và rất kém ở những môi trường khác. Việc thêm điểm phạt nhấn mạnh mô hình có gradient thấp (gần như hội tụ) nhằm đảm bảo quá trình huấn luyện cân bằng giữa các môi trường.
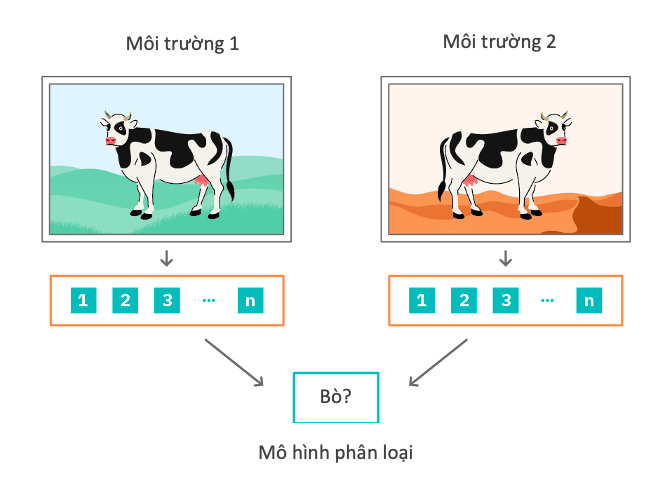
Để hiểu hơn về IRM, chúng ta có thể xem xét thử nghiệm sau. Giả sử ta có một tập dữ liệu hình ảnh của bò và lạc đà, và nhiệm vụ là phân loại chúng. Tập dữ liệu được phân ra theo vị trí địa lý của các hình ảnh: những ảnh được chụp ở vùng đồng cỏ được gộp thành một môi trường, và những ảnh được chụp ở sa mạc tạo thành một môi trường khác.
Một mô hình học có giám sát thông thường được xây dựng để giải quyết bài toán phân loại nhị phân giữa bò và lạc đà. Nguyên tắc học trong học có giám sát là Tối thiểu hóa rủi ro thực nghiệm trên một tập dữ liệu hữu hạn (Empirical Risk Minimization – ERM) nhằm giảm thiểu hàm mất mát cross-entropy thông thường. Chúng ta có thể chắc chắn rằng mô hình sẽ hoạt động tốt trong hai môi trường này vì chúng ta đã cung cấp dữ liệu từ hai môi trường một cách rõ ràng.
Tuy nhiên, vấn đề xuất hiện khi chúng ta muốn xác định một con bò trên tuyết, và nhận ra rằng mô hình phân loại không thực sự học được cách nhận dạng một con bò, mà thay vào đó lại học cách nhận dạng cỏ. Vì vậy mô hình sẽ kém chính xác trong bất kỳ môi trường mới chưa được huấn luyện.

Với IRM, chúng ta thực hiện huấn luyện trên (ít nhất) hai môi trường và bao gồm điểm phạt cho từng hàm tổn thất. Có thể gần như chắc chắn rằng hiệu năng của mô hình trên tập dữ liệu huấn luyện sẽ bị giảm sút. Tuy nhiên, vì được tạo điều kiện để học các đặc điểm bất biến qua nhiều môi trường nên mô hình có nhiều khả năng nhận dạng được những con bò trên tuyết hơn. Thực tế, lý do khiến cho kết quả trong quá trình huấn luyện của mô hình bị giảm là bởi nó không học quá nhiều các mối tương quan giả có thể ảnh hưởng đến dự báo trong môi trường mới.
Không thể đảm bảo rằng mô hình được huấn luyện với IRM tránh được việc học các tương quan giả. Điều này phụ thuộc hoàn toàn vào các môi trường được cung cấp. Nếu một đặc tính cụ thể là một đặc điểm phân biệt hữu ích cho mọi môi trường thì nó có thể được học như một đặc tính bất biến trong mọi môi trường, ngay cả khi trong thực tế nó là tương quan giả. Do đó, khả năng tiếp cận với các môi trường đủ đa dạng là điều thiết yếu để IRM thành công.
Tuy nhiên, chúng ta cũng không nên bất cẩn trong việc gắn nhãn môi trường. Cả ICP và IRM đều lưu ý rằng việc chia tách các biến tuỳ ý trong dữ liệu quan sát có thể tạo ra môi trường đa dạng nhưng đồng thời cũng có thể huỷ hoại những đặc tính bất biến mà chúng ta đang tìm kiếm. Mặc dù IRM đề cao tính bất biến như đặc điểm chính của quan hệ nhân quả, nó vẫn nhắc nhở ta về một mô hình cấu trúc và đặt ra câu hỏi liệu việc định nghĩa môi trường có thể thay đổi quá trình tạo lập dữ liệu hay không.
Những lưu ý khi áp dụng IRM
IRM có khả năng ngoại suy cho các tập dữ liệu mới, trong đó học có giám sát phân bố đồng nhất độc lập có thể (tốt nhất là) nội suy từ chúng. Sử dụng IRM để xây dựng các mô hình cải thiện các thuộc tính tổng quát hoá bằng cách nâng cao hiệu quả của mô hình qua nhiều môi trường, và cho chúng ta một cách biểu diễn đặc tính đầu vào mới và gần với nhân quả hơn. Tất nhiên biểu diễn này có thể không toàn diện (IRM là một quy trình dựa trên tối ưu hoá, và chúng ta sẽ không bao giờ biết liệu mình đã thực sự tìm ra điểm tổn thất tối thiểu trên mọi môi trường hay chưa) nhưng nó vẫn là một bước tiến gần hơn tới cấu trúc nhân quả tiềm ẩn. Điều này có nghĩa là chúng ta có thể sử dụng mô hình để dự đoán dựa trên các mối tương quan nhân quả thực sự thay vì các mối tương quan giả theo từng môi trường cụ thể.
Tuy nhiên, IRM không phải là “phương thuốc chữa bách bệnh” và đi kèm với một số thách thức.
Thông thường tập dữ liệu được sử dụng trong học máy được thu thập trước và ban đầu có thể được dùng cho một mục đích hoàn toàn khác. Ngay cả khi một tập dữ liệu được gắn nhãn tốt đủ để giải quyết vấn đề ban đầu thì nó cũng hiếm khi bao gồm siêu dữ liệu (thông tin về dữ liệu). Do đó, thường không có đủ thông tin về môi trường mà dữ liệu được thu thập nếu dữ liệu được sử dụng để trả lời cho một câu hỏi khác với mục tiêu ban đầu.

Một thách thức khác là tìm kiếm dữ liệu từ các môi trường đủ đa dạng. Nếu các môi trường tương tự nhau, IRM khó có thể học được các đặc tính tổng quát cho các môi trường khác nhau. Có thể coi vấn đề này như hai mặt của một đồng xu – một mặt, chúng ta không nhất thiết phải có những môi trường hoàn toàn khác biệt để IRM hoạt động hiệu quả, mặt khác, chúng ta lại bị giới hạn bởi sự đa dạng của môi trường. Cụ thể, nếu một đặc tính dường như là một yếu tố dự báo tốt trong tất cả các môi trường na ná nhau, IRM sẽ không thể phân biệt được đặc tính đó với một đặc tính nhân quả thực sự. Nhìn chung, càng nhiều môi trường thì IRM sẽ càng hiệu quả hơn trong việc học các đặc tính bất biến và càng tiến gần hơn tới biểu diễn nhân quả.
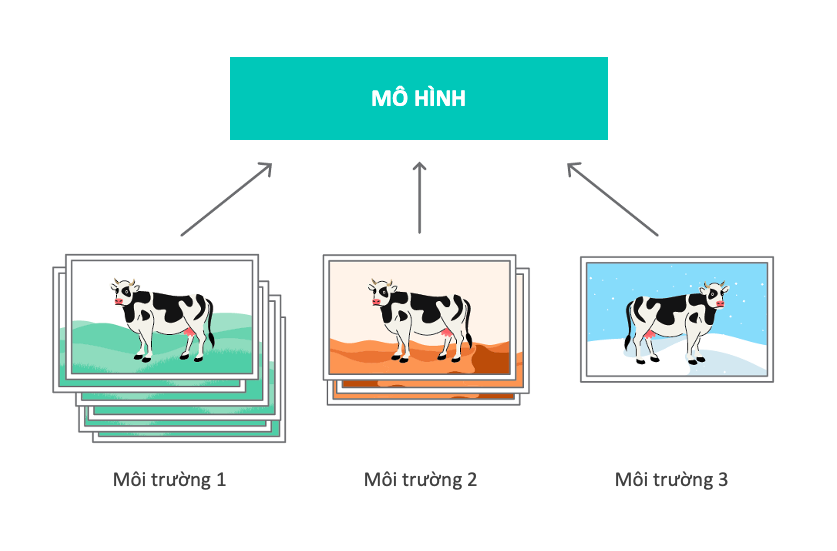
Không có mô hình nào là hoàn hảo, và việc sử dụng mô hình có phù hợp hay không là tuỳ thuộc vào mục tiêu. IRM có nhiều khả năng sẽ tìm ra các đặc tính dự báo bất biến với độ chính xác ngoài phân phối tốt hơn ERM (phương pháp học giám sát thông thường), nhưng IRM sẽ phải đánh đổi bằng độ chính xác dự đoán trong môi trường huấn luyện.
Đối với một số lĩnh vực áp dụng cụ thể, chúng ra hoàn toàn có thể rất chắc chắn rẳng dữ liệu trong phân phối thử nghiệm cuối cùng (trong tự nhiên) sẽ phân phối giống như dữ liệu huấn luyện. Thêm vào đó, chúng ta có thể đơn giản chỉ muốn một mô hình dự đoán thay vì can thiệp. Nếu cả hai điều này đều thoả mãn, chúng ta chỉ cần một mô hình học giám sát với ERM và khai thác tất các mối tương quan giả có thể có.
Comments