Dự đoán Nhân quả Bất biến
SUY LUẬN NHÂN QUẢ CHO HỌC MÁY - KỲ 11
Bài viết này thuộc chuỗi bài viết về “Suy luận Nhân quả cho Học máy”. Hãy cùng đọc thêm các bài viết có cùng chủ đề tại đây
Để hiểu thêm kiến thức về Suy luận Nhân quả, hãy cùng tìm đọc chuỗi bài viết về “Suy luận Nhân quả với Python” tại đây và “60 Giây Nhân quả với Python” tại đây
Dự đoán nhân quả bất biến (Invariant Causal Prediction - ICP) sử dụng khung lý thuyết mô hình nhân quả cấu trúc (SCM).
Thông thường, đại lượng chúng ta quan tâm nhất trong phân tích nhân quả là tác động nhân quả của một can thiệp: biến mục tiêu thay đổi như thế nào khi một biến khác thay đổi? Để tính toán đại lượng này, chúng ta cần phải giữ cố định giá trị một số biến, hoặc phải xử lý nếu chúng thay đổi. Nếu chúng ta chỉ quan tâm đến các nhân tố chi phối một mục tiêu cụ thể, chúng ta không cần xây dựng toàn bộ biểu đồ mà chỉ cần xác định những yếu tố nào thực sự là nguyên nhân trực tiếp của mục tiêu. Một khi làm được điều này, chúng ta có thể trả lời các câu hỏi nhân quả, như mức độ đóng góp vào tác động nhân quả của từng biến, hoặc tác động nhân quả của việc thay đổi một trong các biến đầu vào.
Điều mấu chốt ICP đưa ra là vì các mối quan hệ nhân quả trực tiếp là bất biến, chúng ta có thể xác định các nút cha mẹ của quan hệ nhân quả (nguyên nhân trực tiếp). Cách thiết lập tương tự như trong học máy; chúng ta có một số thuộc tính đầu vào và muốn xây dựng một mô hình để dự đoán mục tiêu đầu ra. Khác với học có giám sát, mục tiêu ở đây không phải tính chính xác của mô hình khi dự đoán biến mục tiêu. Trong ICP, chúng ta cố khám phá quan hệ nhân quả trực tiếp tác động lên một biến cho trước – các biến trực tiếp chĩa vào một mục tiêu trong biểu đồ nhân quả.
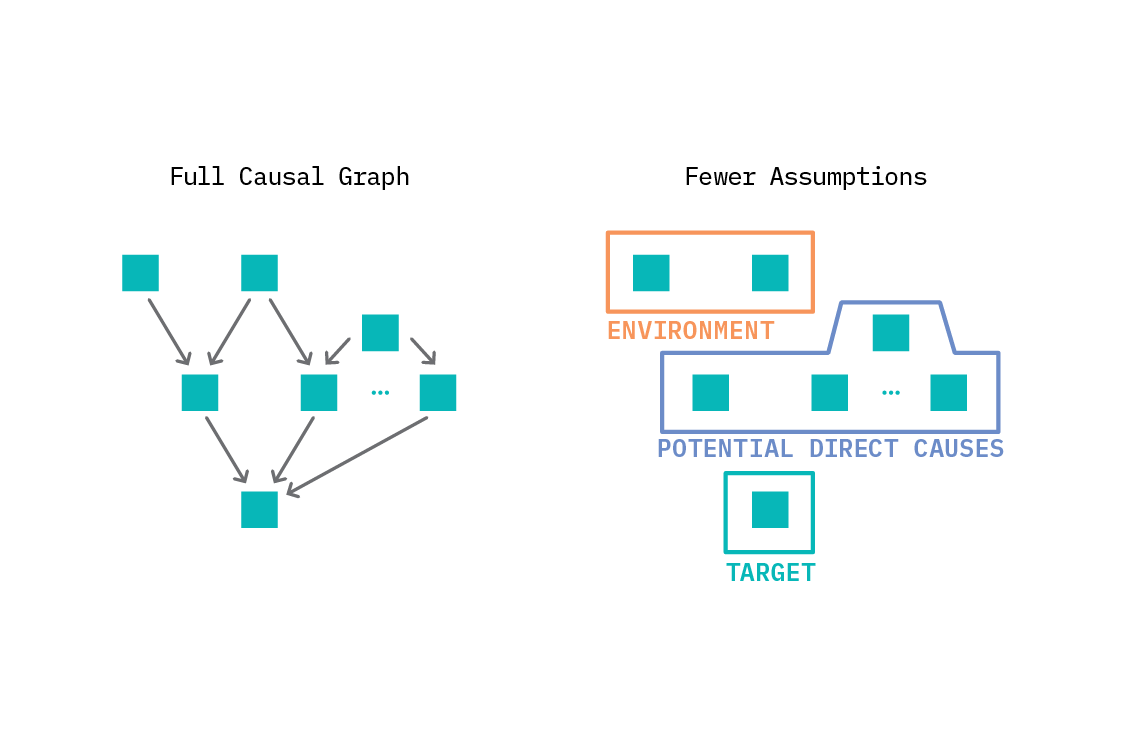
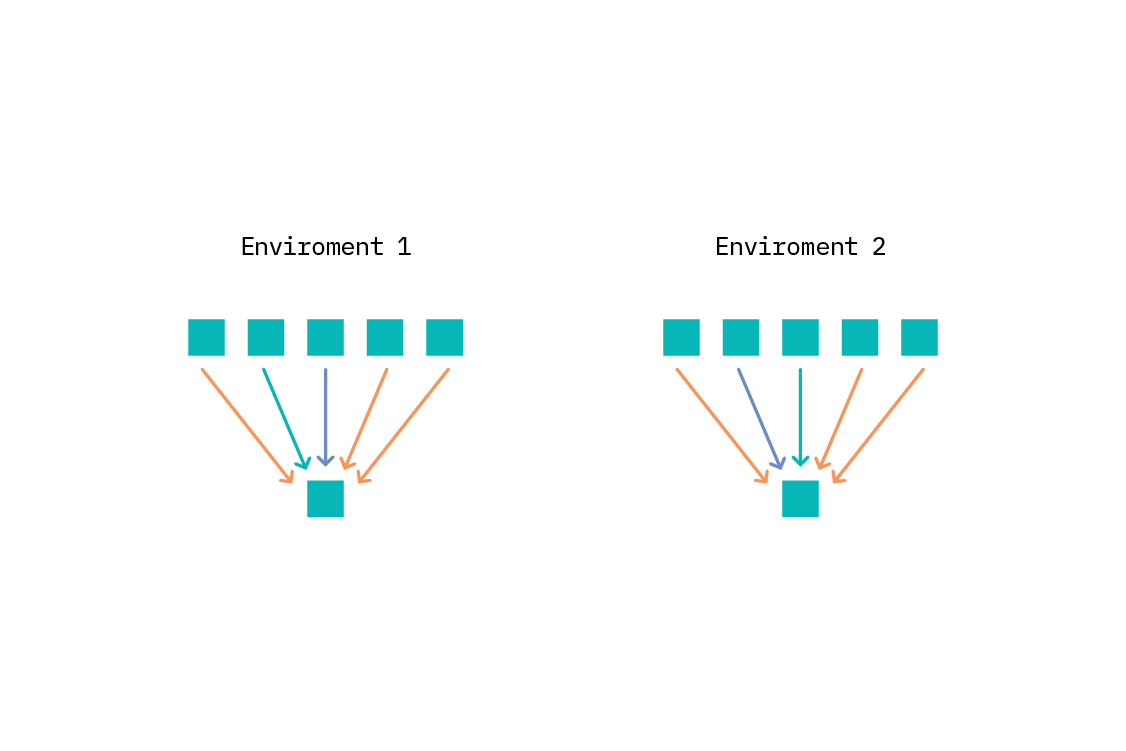
Để sử dụng ICP, chúng ta xác định biến mục tiêu và thiết lập một danh sách phù hợp liệt kê các mối quan hệ nhân quả trực tiếp tiểm năng của biến đó. Sau đó, chúng ta cần định nghĩa môi trường nên vấn đề đươc đặt ra: mỗi môi trường là một bộ dữ liệu. Theo ngôn ngữ của SCM, mỗi môi trường tương ứng với dữ liệu được quan sát khi một can thiệp cụ thể được kích hoạt ở một vị trí nào đóChúng ta vẫn có thể suy luận mà không cần xác định toàn bộ biểu đồ, hoặc thậm chí xác định can thiệp cụ thể nào đang được kích hoạt, miễn là chúng ta có thể chia dữ liệu ra thành các môi trường. Trong thực tế, chúng ta thường lấy một biến quan sát làm biến môi trường miễn là nó hợp lý.
Ví dụ, khi chúng ta muốn dự đoán doanh số bán lẻ và muốn phân biệt liệu thuộc tính của cửa hàng có tác động nhân quả đến doanh số bán hàng hay không. Mục tiêu là doanh số bán hàng, và nguyên nhân tiềm năng có thể là các thuộc tính như quy mô của hàng, số lượng đối thủ cạnh tranh trong cùng khu vực, số lượng nhân viên, v.v.
Môi trường có thể là các tỉnh khác nhau (hay thậm chí các quốc gia) – hay bất kỳ điều gì ít khả năng ảnh hưởng trực tiếp đến doanh số bán hàng, nhưng có thể ảnh hưởng đến các thuộc tính tác động đến doanh số. Ví dụ, địa điểm khác nhau sẽ có mật độ dân số khác nhau, và mật độ dân số có thể là một nguyên nhân tác động tới doanh số bán hàng. Quan trọng là môi trường không thể là đích đến (nút con) của biến mục tiêu.
Để áp dụng ICP, trước tiên chúng ta xem xét một tập con các thuộc tính. Sau đó, ta chạy một hồi quy tuyến tính (Gaussian) từ tập con này cho mục tiêu trong từng môi trường đã được xác định. Nếu mô hình không thay đổi giữa các môi trường (có thể đánh giá thông qua việc kiểm tra các hệ số hay phần dư), chúng ta tìm thấy một tập hợp các thuộc tính có thể dẫn tới dự đoán bất biến. Chúng ta lặp lại trên các tổ hợp tập con các thuộc tính được chọn. Các thuộc tính xuất hiện trong mô hình bất biến là nguyên nhân hợp lý của biến mục tiêu. Giao điểm của các nhóm nguyên nhân hợp lý này (các thuộc tính có tính dự báo trong mọi môi trường) sau đó tạo nên một tập hợp các nguyên nhân thực trực tiếp.
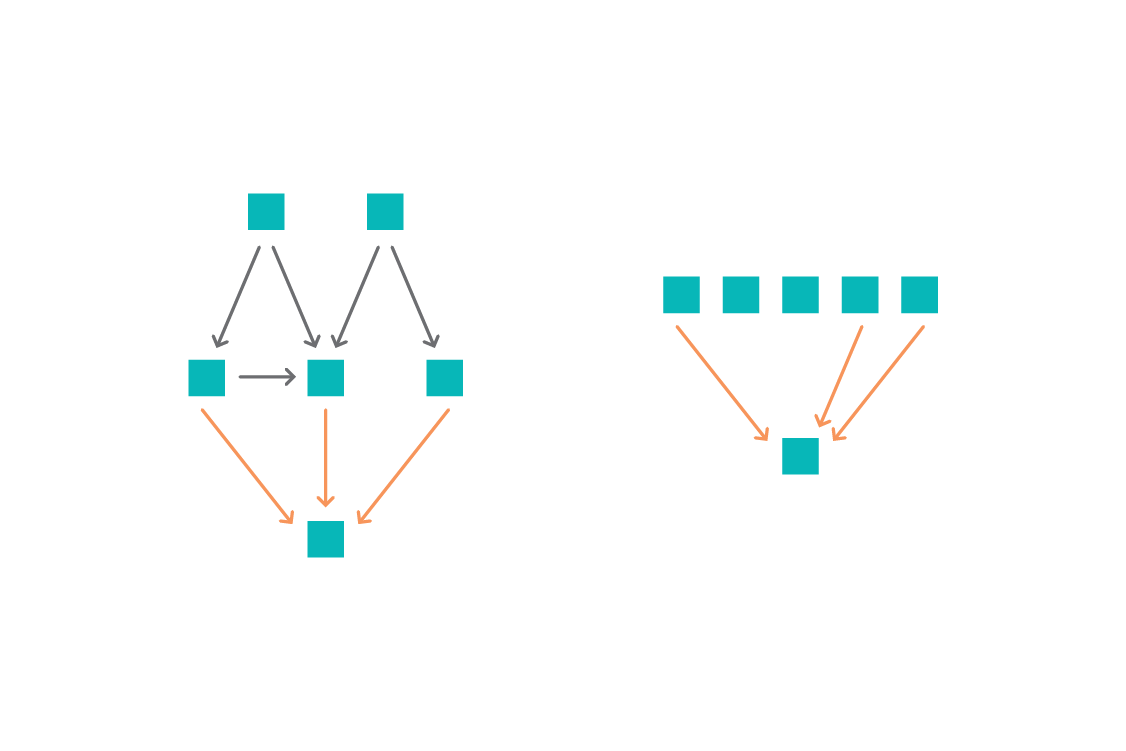
Theo thuật ngữ học máy, ICP về cơ bản là một phương pháp lựa chọn thuộc tính, trong đó các thuộc tính được chọn có khả năng cao là nguyên nhân trực tiếp của mục tiêu. Mô hình được xây dựng trên các thuộc tính này có thể được diễn giải theo quan hệ nhân quả: những thuộc tính có hệ số cao có nghĩa là chúng có tác động nhân quả lớn đối với mục tiêu, và sự thay đổi của những thuộc tính này sẽ dân tới sự thay đổi được dự đoán của mục tiêu.
Đương nhiên ICP vẫn tồn tại một số hạn chế và dựa trên một số giả định nhất định. Cụ thể, chúng ta phải giả định rằng không có biến nhiễu không thể quan sát giữa các thuộc tính và mục tiêu (biến nhiễu là nguyên nhân chung của thuộc tính và mục tiêu). Nếu có những biến nhiễu đã được quan sát, chúng ta phải thực hiện một số điều chỉnh để xử lý chúng, như đã nêu chi tiết trong bài báo về ICP. Các tác giả cũng cung cấp một package trong R để thực hiện phương pháp này.
Hạn chế trong việc sử dụng mô hình Gaussian tuyến tính – và các môi trường rời rạc, thay vì được xác định bởi giá trị của một biến liên tục – được loại bỏ bởi ICP phi tuyến tính. Trong trường hợp phi tuyến tính, chúng ta thay việc so sánh các phần dư hoặc hệ số bằng các phép thử độc lập có điều kiện.
Comments